Traditionally data analysis has been done on Relational Database Management Systems (RDBMS) which work on data with a clearly defined structure since they require a schema definition before the data can be loaded.
RDBMS also scale better vertically rather than horizontally, meaning scaling is done through using higher capacity machines rather than spreading the load through many machines as replication of RDBMS data across the machines tend to be problematic.
Since the RDBMS clusters are made up of small numbers of high end machines, the data needs to be brought to the computation units (the RDBMS servers in the cluster)
Big Data is characterized by three Vs - velocity, volume and variety. There is a need of handling data that is produced in massive volumes (huge and exponentially growing data sets of upto Petabytes that make storage an issue and very dificult to bring the data to the computation units) at very high speeds and completely unstructured (videos, pictures, text etc). Therefore this kind of data does not lend itself very well to be processed through traditional RDBMS.
Hadoop is an open source framework that facilitates storage of data in a cluster of distributed commodity hardware and process them in parallel - it provides a reliable, scalable platform for storage and analysis.
Through HDFS Hadoop divides the data into small chunks, called blocks, and distributes it, replicated, throughout the cluster. This way the data is stored in small capacity drives, as disk seeking time has not improved significantly as the disk sizes over the years hance reading big blocks of data from large disks is a lot slower than reading small blocks from smaller drives. And through MapReduce Hadoop brings the processing power to where the data is, hence the data is always local to the processing unit avoiding moving huge chunks of data through the network.
Hadoop (through it’s MapReduce framework) is really geared towards batch processing of very large data sets, it is not suitable for interactive analysis of data because you can’t query and get results back in a few seconds, queries typically take minutes or more. However with the introduction of YARN in Hadoop 2 new processeing models have been made possible, such as Interactive SQL through Impala and Hive and **Stream and Iterative processing through Spark
History
Hadoop was created by Doug Cutting, the creator of the widely used text search engine Apache Lucene and Mike Carafella while working on an open source web crawler called Nutch. Storing and processing the huge amounts of data collected by the web crawler quickly became an architectural issue while working on Nutch and when Google published papers on the Google File System (GFS) and MapReduce the team adopted the technologies within their work to combat the scaling challenges.
Hadoop was later spun out as an independent project for generic storage and processing of large amounts of data and not just indexed web content from Nutch, containing HDFS (from Google’s GFS) for storage and MapReduce (from Google’s MapReduce) for computation. In version 1 of Hadoop MapReduce was implemented in Java and natively ran Java code for mapper and reducer scripts, although other languages, like Python etc, were supported through Hadoop Streaming it wasn’t until the inclusion of YARN in Hadoop 2 that native programming using languages like Python and Scala was possible.
Architecture
Hadoop’s main components (since Version 2) is HDFS as the distributed file system, MapReduce as the distributed computing engine and YARN as the distributed resource manager.
Hadoop’s infrastructure takes care of all the complex aspects of distributed processing like parallelization, scheduling, resource management, inter-machine communication, handling software and hardware failures etc and creates a clean abstraction layer allowing simpler implementations of distributed applications that process terabytes of data on huge clusters of machines.
HDFS
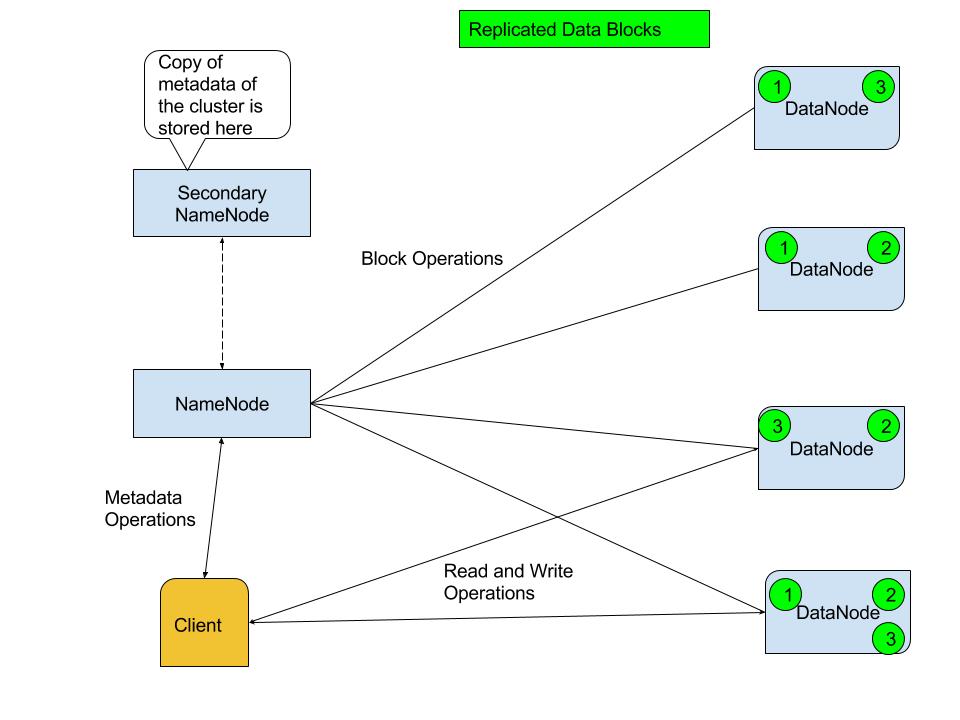
HDFS is a highly fault tolerant file system that is designed to be deployed on a large number of commodity hardware, allowing it to scale to accomodate huge data sets. An HDFS cluster has a single active NameNode, which is the master server that stores metadata about the filesystem, including the files hierarchy, size of the files and permissions. There is usually a backup server that runs as a standby NameNode in case the active NameNode becomes unavailable, the standby NameNode keeps a copy of the entire metadata held in the active NameNode.
The NameNode also manages and maintains the DataNodes, which are the slave servers that store the actual data and respond to read/write requests from clients.
HDFS Architecture
Horizontal scaling is achieved by adding more commodity hardware as DataNodes to the cluster.
HDFS stores data in blocks of 128 MB (by default, this can be changed through configuration), which are replecated across three DataNodes (again this is the default configuration which can be changed) for redundancy. Large files are broken down to 128 MB blocks before thay are stored in the cluster.
Variety of data structures, such as text, videos, photos etc, are supported as HDFS does not enforce a schema before writing data. This allows fast “dumping” of data into the HDFS cluster and makes Hadoop particularly suitable for write-once read-many types of applications.
MapReduce
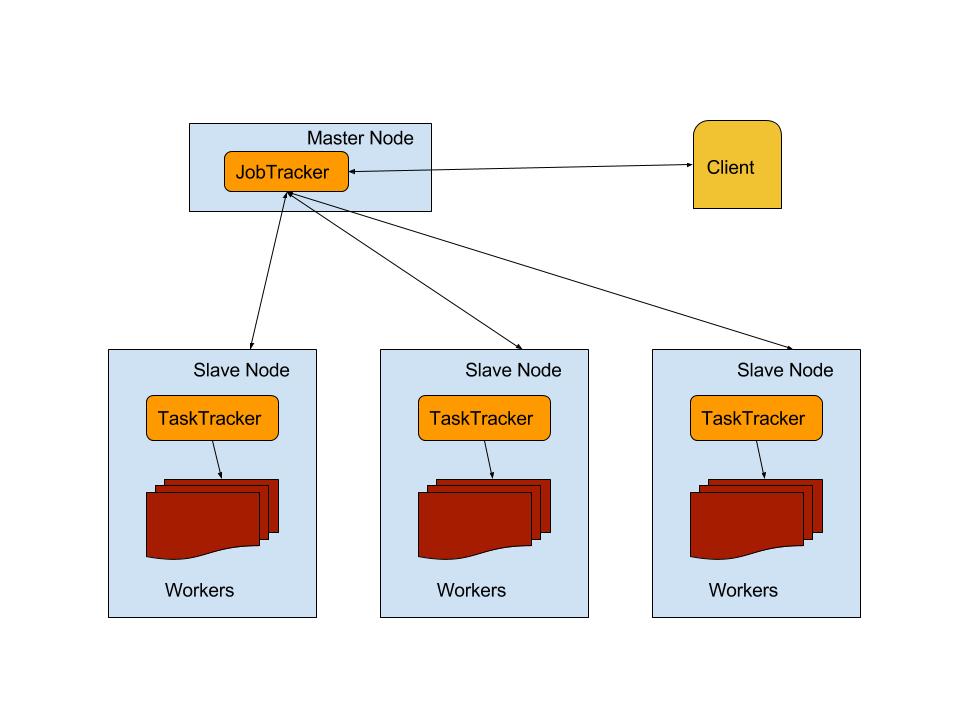
MapReduce is both a programming paradigm as well as a framework for easly processing data in parallel on a dsitributed cluster in a reliable and fault tolerant manner. The MapReduce framework consists of a JobTracker and TaskTrackers, the TaskTrackers in the cluster handles the execution of jobs in the actual cluster nodes that run HDFS’s DataNodes hence bringing the computation to where the data is stored.
The MapReduce programming paradigm involves splitting the input data into independent chunks that are processed in parallel through the mappers . The JobTracker will split the jobs and send them to the TaskTrackers running in the nodes that have the data to be processed. These mappers run on the cluster nodes where TaskTrackers are running and will output key-value pairs, called intermidiate records, that are stored back in the HDFS. The outputs are then put through a shuffling and sorting step before being reduced into a single result through reducers, this result is then stored back into HDFS
MapReduce Platform Architecture
Read more articles on MapReduce
YARN
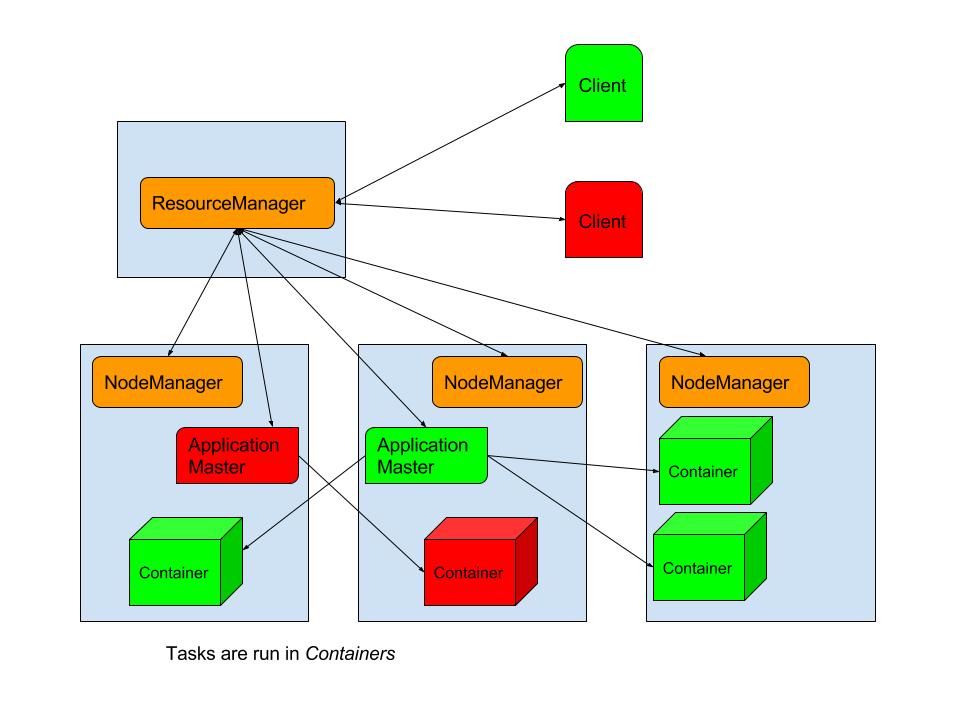
The MapReduce platform architecture of a single JobTracker which manages computational resources in the cluster as well as coordination of all tasks runing on a cluster causes the JobTracker to become a bottleneck for huge clusters (5,000 nodes and 40,000 tasks according to Yahoo) and hance limiting the scaling of the platform. MapReduce also do not use their computationl resources with optimum efficiency and is designed to only run Map-Reduce jobs. These drawbacks were addressed with the release of YARN in Version 2 of Hadoop
in YARN architecture a global ResourceManager keeps track of live NodeManagers and available resources, allocating available resources to applications and tasks. The ResourceManager usually runs on a dedicated machine in the cluster while the NodeManagers run on every node in the cluster that has HDFS DataNode running. The NodeManagers provide computational resoruces in form of conatiners and manages the processes running in those containers.
YARN also has Application Masters which are per-application and negotiate resources with the ResourceManagerand works with the NodeManagers to execute and monitor the tasks. This separation of concerns allows YARN to scale to bigger Hadoop clusters than the older MapReduce framework allowed.