Apache Spark is a fast and general engine for large-scale data processing. As I wrote on my article on Hadoop, big data sets required a better way of processing because traditional RDBMS simply can’t cope and Hadoop has revolutionized the industry by making it possible to process these data sets using horizontally scalabale clusters of commodity hardware.
However Hadoop’s own compute engine, MapReduce, is limited in having a single programming model of using Mappers and Reducers and also being tied to reading and writing data to the filesystem during the processing of the data which slows down the process. When Hadoop introduced YARN it opened doors to other programming models to be run on top of Hadoop, and make use of HDFS as the distributed file system, one of which is Apache Spark which has the following advantages over Hadoop’s MapReduce
- It has an advanced DAG execution engine that supports acyclic data flow and in-memory computing. Loading and processing the data in-memory instead of relying on read and write to the file systems allows Spark to run up to 100x faster than Hadoop’s MapReduce
- It supports more than just MapReduce, Spark comes bundled with libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming, which can be combine seamlessly in the same applications making complex solutions easy to develop

- While Hadoop’s MapReduce only natively supports Java applications, Spark natively supports Java, R, Scala and Python, with rich APIsfor all. Spark comes with built in interactive shells for Scala, Python and R. This makes Spark a solid platform to easily develop on multiple languages without the need of workarounds like Hadoop Streaming.
- It can run on Hadoop’s YARN platform but also it can run stand alone cluster and on a host of other platforms, including Apache Mesos and Amazon’s EC2. It also can access data from any Hadoop data source including HDFS as well as other databases like Cassandra, HBase, Hive, Amazon’s S3 etc. This makes it more flexible in terms of the infrastructure it will be deployed to.
- While Hadoop’s MapReduce is really suitable only for batch processing of data, Spark can be used for both batch processing as well as real-time processing because of how fast the data can be processed in-memory making it suitable for applications that require a result in a few seconds.
- Spark uses lazy evaluations with optimizations making it a lot faster especially in applications that have multi pass workflows. In MapReduce each step in these work flows will have it’s own map and reduce steps writng data back to HDFS in each pass. In Spark everything is executed in-memory with lazy evaluation allowing Spark to optimize the setps before they are run.
Use Cases
As a distributed general purpose cluster computing framework with in-memory data processing engine Apache Spark is a suitable platform for many solutions that involve large data sets
- Extract, Transfrom and Load (ETL) workloads can be processed as batch jobs since Spark can handle data processing in batch just as well as near real-time streaming. And due its ability to easily integrate with various data sources, like Hive, Cassandra etc, as well accessing data through numerous ways, like HDFS, S3 etc, Spark makes developing ETL solutions simple.
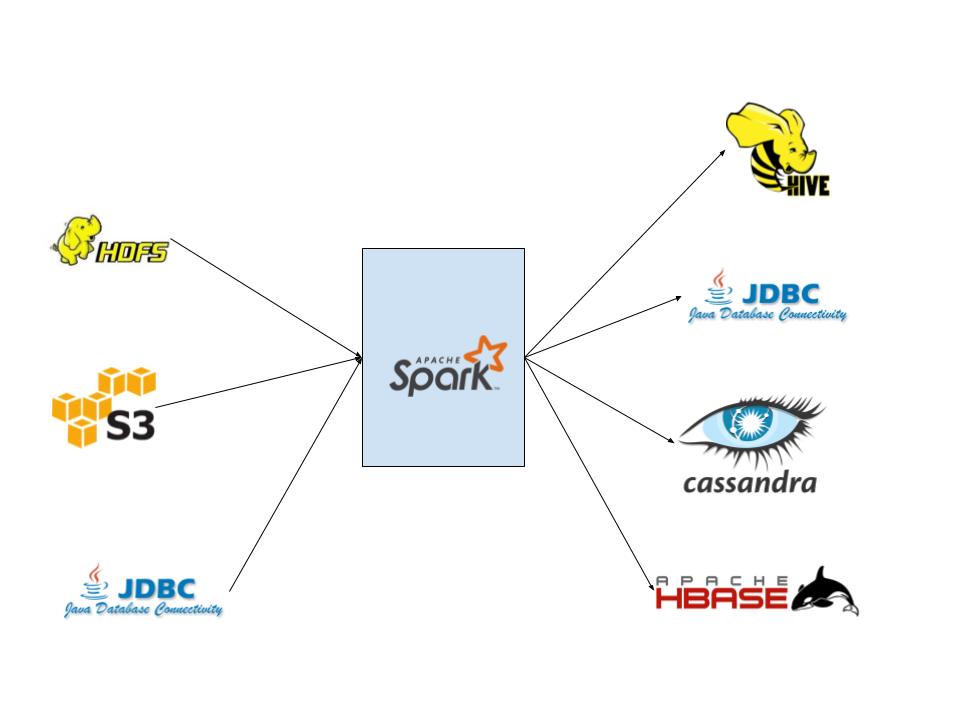
Spark ETL integrations
- Due to its in-memory computing engine, near real-time interactive analytics applications can be run through Apache Spark Streaming with ease.
- Marchine Learning applications are easier to use with the built in MLlib library in Spark. The iterative and multi-pass nature for Machine learning applications (retrainig models etc) makes Spark a lot more suitable for such applications than Hadoop’s MapReduce platform.
- Spark’s built in Graph processing library (GraphX) makes it easier for developers to build applications that exploit graph analytics
- The rich, unified, well designed API available in multiple languages makes it easy for developers to build Spark applications. Developers can write concise and simple code in languages that are popular in the data science community (such as Python and Scala) using Spark’s powerful APIs describgin the whole application instead of having to write long-winded Java code in numerous scripts to get the same results. This makes Spark very easy to adopt.
- Spark’s flexibility on a platform to run on (Stand Alone, Hadoop YARN, Apache Mesos, Amazon EC2, etc) makes it easy to deploy on various production systems to fit the environment the Spark application is deployed to.
Architecture
Spark’s core runs on multiple environments from a stand alone cluster to on top of Hadoop Yarn, Apache Mesos or Amazon’s EC2 instances. On top of the core sits the Spark SQL, Spark Streaming, GraphX, MLlib and more recently (from version 2.2.0 of Spark) the SparkR libraries.
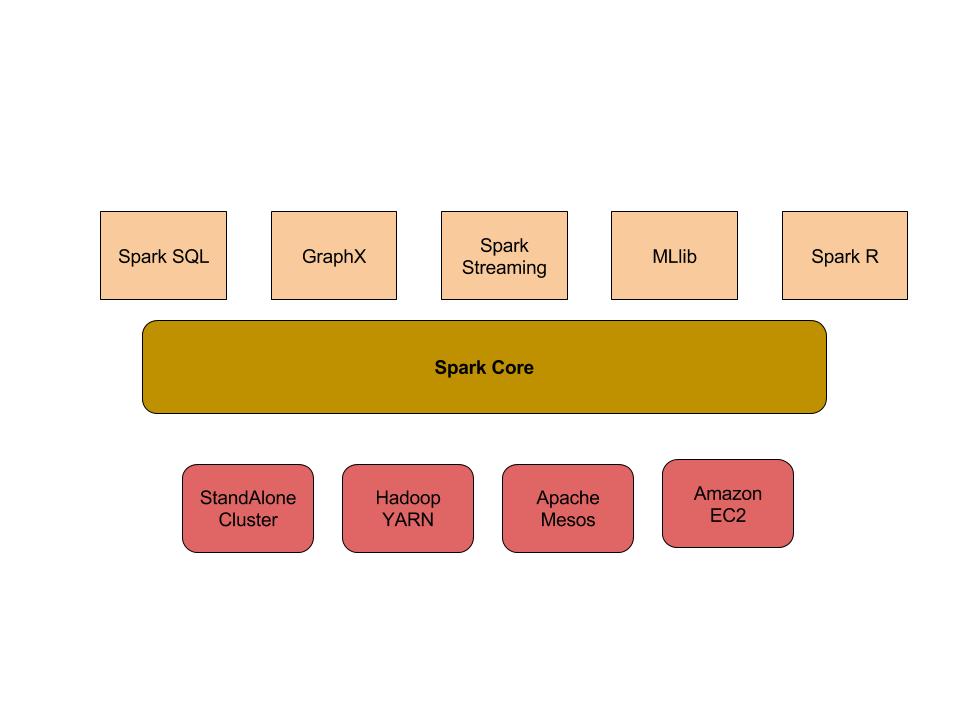
High Level View of Spark Architecture
The core of Spark provides the Resilient Distributed Dataset (RDD) data structure which is an abstraction layer made up of collections of fault tolerant elements partitioned accross the nodes of the cluster that can be operated on in parallel. RDDS have the following properties;
- They are immutable, all transformations made on them result in new RDDs being created
- They automatically recover from node failures so developers do not need to implement error recovery routines for node failures
- RDDs may be persisted in memory so that it may not be recomputed the next time it is referenced
An RDD can be created in Spark in one of two ways, by parallelizing a collection in the driver program or by referencing a data set in an external storage such as HDFS, HBase or any data source offering a Hadoop Inpt Format
Read more articles on Apache Spark
comments powered by Disqus